Feature Adoption Report with Segment, BigQuery and R
In product development our focus should be on providing value to the customer, and not just blindly piling on features to the product. A simple, if not always accurate, way of measuring whether a given feature provides value to the customer is to look at the adoption — that is, what percentage of your users are using the feature.
In this post I will show you what my feature adoption report looks like, and how you can implement a subset of it with R, Segment and Google BigQuery.
The Feature Adoption Report
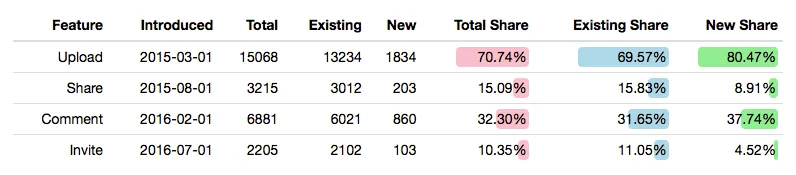 Example of the feature adoption report as it might look for an image sharing service.
Example of the feature adoption report as it might look for an image sharing service.
The report shows data for the previous calendar month, and for each feature it tells you when the feature was introduced, the total number of active users during the previous month, and how big a share of all your users that corresponds to.
This allows you to take a high-level look at the features you introduce, and helps you evaluate whether they are succesful or not. If a feature has low adoption, you might want to consider removing it again, or, if you still think it is important, divert attention to improving the adoption.
Arranging features by their introduction date is important. In product development we might talk about our “hit rate” — that is, how often a feature we launch is succesful. Arranging the feature report in this way makes it very easy to ascertain the cadence of your successes.
New vs. Existing Users
Additionally the report takes each feature and segments all users into two sets:
- Existing users — users that were already users when this particular feature was introduced.
- New users — users that joined after this feature was introduced.
This allows the report to give you two useful numbers:
- Existing Share — of all the users that existed when this feature was introduced, what percentage used the feature last month.
- New Share — of all the users that joined after the feature was introduced, what percentage used the feature last month.
Those numbers enables a more nuanced discussion. A specific feature might have a low overall adoption, and a low adoption with existing users, but a large adoption with new users. This may have multiple causes, two options being:
- The feature expands the appeal of the product to a new type of user.
- Product marketing to existing users is lacking.
Often it is a combination of those two things, but you might intuitively have an idea of which is the main cause, otherwise you have some user research to do.
It Doesn’t Do Much
The feature adoption report does not show complicated engagement scores, nor does it show realtime down-to-the-minute numbers. It is not a tool you can use to “growth hack” your product. What it does allow is a high-level, yet nuanced, discussion about the direction of your product, and the succes of your previous efforts.
R, Segment and BigQuery
In the following we will implement a subset of the feature adoption report using what has become my preferred stack for product analytics: R Notebooks, Segment and BigQuery.
R and R Notebooks are powerful tools for data analysis, and ggplot is probably one of the best and most powerful ways to create graphs. Additionally, R makes it very easy to combine data from disparate sources. E.g. you might want to take data from your own relational database and combine it with data from the Google Analytics HTTP API. This can be difficult, or even impossible, with other tools but is a breeze with R.
Segment is something akin to an industry-standard, making it very easy to collect data from various services and send them to a single data warehouse. Segment comes with a ton of integrations, and for most commonplace services it is a one-click operation to start collecting data from them.
At Firmafon we were using Redshift for our data lake, but recently we switched to BigQuery, and for our use it is superior. With BigQuery you pay a minimum for storage, and mostly pay for the data that you actually query. This makes it a great fit for product analytics, where you only run your reports occasionally. With Redshift we had an instance running 24/7. We went from spending several hundred dollars each month on Redshift to spending $1/month on BigQuery.
Show Me the Code
I assume that you are already tracking events in Segment with BigQuery as a Warehouse, and that you can tell whether a user uses a given feature by a single event. Create a new R Notebook in RStudio, install the required packages and load the Tidyverse:
install.packages("tidyverse", "dbplyr", "bigrquery", "lubridate", "formattable")
library(tidyverse)Now we will establish a connection to BigQuery. It will open a browser window and use OAuth for authorization — no need for API keys or anything else.
project_id <- "your-google-cloud-project-id"
bigquery <- DBI::dbConnect(
bigrquery::bigquery(),
project = project_id,
billing = project_id
)Next, we will define our features and their corresponding Segment events in a tibble.
features <- tribble(
~feature, ~event,
'Upload', 'uploaded_image',
'Share', 'shared_image',
'Comment', 'posted_comment',
'Invite', 'invited_friend'
)For our analysis, we will only look at data from the previous month. We will get a row for each (feature, user) dyad. We are using dbplyr to generate the SQL:
last_month <- lubridate::floor_date(Sys.Date() - months(1), 'month')
table <- "{your-schema}.tracks"
events <-
tbl(bigquery, table) %>%
filter(
date_trunc(date(sent_at), MONTH) == last_month,
event %in% features$event
) %>%
select(event, user_id) %>%
distinct() %>%
collect()We are interested in the share of our total active users that use a given feature, so we need to calculate our total number of active users. In this case we simply look at the number of unique user id’s across all features.
total_users <- events %>%
distinct(user_id) %>%
nrow()An interesting side-note is that this number does not include users that didn’t use your app at all last month. You might be interested in seeing feature adoption as a share of your total number of users, including inactive users. In that case, you could pull out that number from your own datastore. This is easy to do with R.
At this point we group the data by each event, count the number of active users for that feature, calculate the share of the total number of users and join the resulting tibble with the original features tibble, to get the feature name.
by_feature <- events %>%
group_by(event) %>%
summarize(
active_users = n(),
active_share = n() / total_users
) %>%
arrange(desc(active_share)) %>%
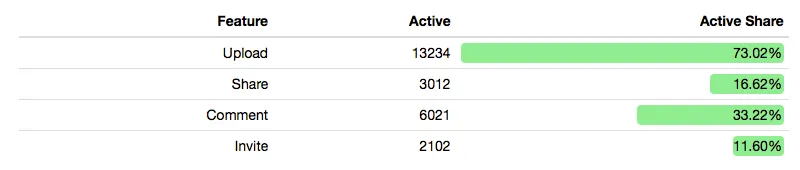
left_join(features)To present the data, we use the excellent formattable package. Amongst other things it allows us to inline a bar chart in the table, providing an easy, visual overview of the popularity of each feature.
by_feature %>%
transmute(
Feature = feature,
"Active Users" = active_users,
"Active Share" = formattable::percent(active_share)
) %>%
formattable::formattable(list(
"Active Share" = formattable::proportion_bar('lightgreen')
))Which should output a table resembling this:
What’s Next?
It is important to have in mind that feature adoption is not a perfect proxy for the value your feature provides. Some products are most valuable if the user never has to touch it again after it has been set up, and a feature might have a low overall adoption, while being crucial for a small subset of customers bringing in a large amount of revenue. What would happen if we measured features not by the number of users, but looked at how much revenue the feature was responsible for? And how do we attribute revenue to a specific feature? Those are some of the questions I hope to explore in future revisions of the feature adoption report.
Questions, ideas, or feedback? I'd love to hear from you at harry@vangberg.name.